Do happy employees bring you happy customers? (Answer: In general – No!)
“Everybody knows that happy employees make happy customers.”
“Satisfied employees are the single most important driver of customer satisfaction.”
In reality, I don’t believe employee satisfaction even makes the top three for most businesses. And I think I can prove it.
This is the third year in a row that I have studied the relationship between customer and employee satisfaction for large companies that sell to US consumers. The results have been consistent: There is almost no relationship between employee and customer satisfaction across the 398 business covered this year. Employee satisfaction explains just 6% of the variation in customer satisfaction across these companies. Mind you, “Almost no relationship” is better than my findings in 2017, which were simply that there was, on average, no relationship.
Within the overall results there are exceptions and surprises. There are industries and entire sectors where employee satisfaction matters a lot more. There are also striking examples of companies whose employees hate them while their customers love them. The opposite is also true. And these are big names.
Let’s begin
Back in 2017 I asked myself whether there was any actual evidence for the many statements that I could find that were similar to those at the top of this article. What I found was highly disappointing, to say the least. I found low-volume studies. I found attractive anecdotal studies based on single companies. I found low-volume and single-company studies about employee engagement, which is a different subject. More on employee engagement later. In short, the whole subject had not been studied scientifically. Repeating my searches before writing this article gave the same result. Nothing useful.
It is not surprising that the subject is tricky to study. Companies do not disclose the results of their own internal employee surveys. High-volume public benchmark data about customer satisfaction is also rare. However, it does exist, as does a single high-volume source of employee satisfaction data. I use Glassdoor data for employee satisfaction and the American Customer Satisfaction Index data for customer satisfaction. This year I was able to match the two for 398 businesses. Here are the highlights:
Overall results
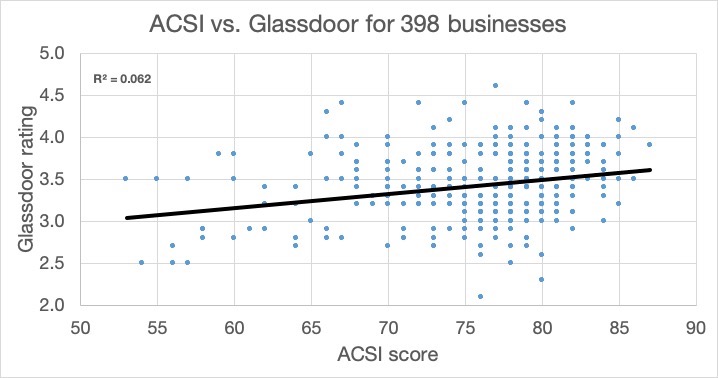
At the top level and across all businesses, variations in employee satisfaction explain 6.2% of the variations in customer satisfaction. However, I somewhat arbitrarily decided that 129 of these businesses, such as hotels, retail stores and airlines, are ‘high-touch’. By this I mean that employees have regular face-to-face contact with customers, where their smiles and empathy may make a difference. The remaining 269 are ‘low-touch’. I have used quadratic regression for the graphs below and think they are interesting.
High-touch businesses
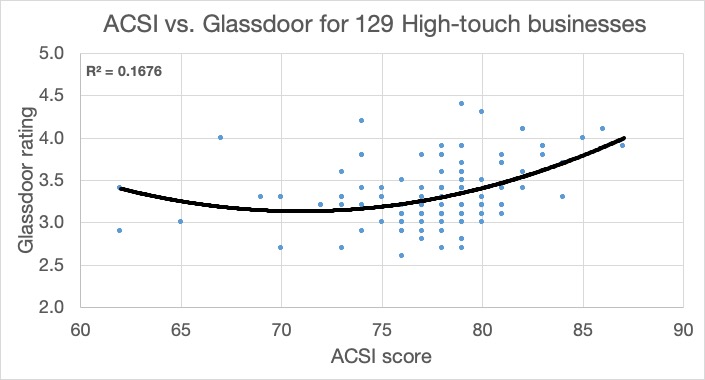
For the high-touch businesses, variations in employee satisfaction explain 16.8% of the variations in customer satisfaction. Among well-represented industries, the nine hotel chains top the list at 61.8%, followed by 17 supermarket chains at 49.1%.
Low-touch businesses
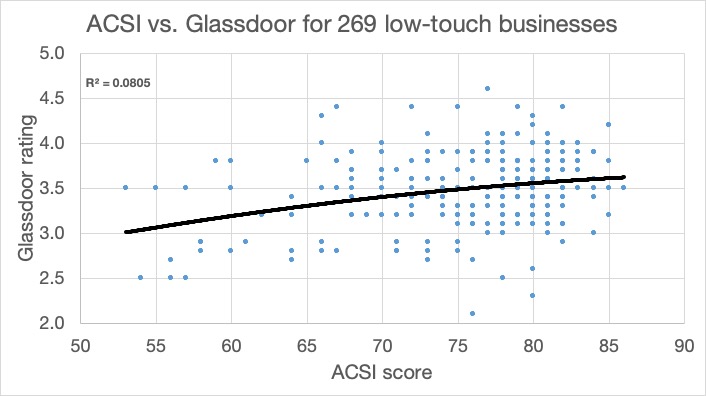
At the other end of the scale, low-touch industries have an average of 8% interdependency between employee and customer satisfaction. The energy utilities industry is represented by 23 companies and shows no relationship at all. I don’t find this surprising. When was the last time you spoke face-to-face with an energy company employee? In my own case, they don’t even need to come out to read our meters anymore.
Performance by industry sector
ACSI data is provided by company and by industry, and the industries are grouped into sectors. Some sectors do better than others as you can see in this table:
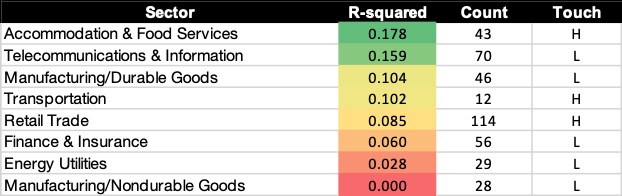
Retail does rather worse than last year. While it might be tempting to say that this is because Internet Retail is now included in Retail, that’s not the problem. Health and Personal Care stores now have no relationship between employee and customer satisfaction.
Performance by Industry
I removed all industries represented by less than five businesses from the table below. This may not be entirely fair. After all, if there are only three large businesses in a particular industry in the USA, the ‘Normal distribution’ rules of statistics don’t apply. If there are only three and you cover them all, you have a good sample. Similarly, there simply aren’t 30 major hotel businesses in the USA, so any preconception you may have that you need a minimum of 30 for a valid sample is simply wrong. In any case, you will be able to make your own judgments when you download the data.
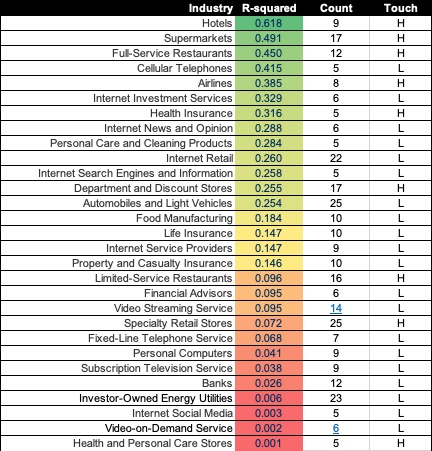
It should not surprise you to see hotels, supermarkets and restaurants at the top of this list. For hotels, employee satisfaction variation explains 61.8% of the variation in customer satisfaction. Employees are an integral part of the experience in these industries. For many of the industries close to the bottom, we never come into face-to-face contact with the employees, so the lack of a relationship between employee and customer satisfaction should not be a surprise either.
This is part one. What’s next?
This is the first instalment. Here is a link to the data so you can download it and do your own analysis. Note that the Excel sheet has four tabs. In the next article I will cover the companies that employees love while customers hate them, and vice-versa. I believe these lists will be quite enlightening and will make it seem more logical that employee and customer satisfaction do not necessarily go together. I will also provide details of the companies that are at the top of both lists, and of course the opposite. I also go on to suggest why these results should not be a surprise.
If you enjoy this sort of thing, there is lots more on this topic and many others in our book Customer Experience Strategy – Design and Implementation. All of our books are available in paperback and Kindle formats from Amazon stores worldwide.