
NPS (33) – Why not ask your employees what your customers want? (ceNPS) – 33rd article in a series on the Net Promoter System®
Welcome to the 33rd article in my series on the Net Promoter Score and System. I want to introduce a new concept this time. I call it ceNPS and here is what it is about: Your employees have quite a bit of knowledge about your customers. Why not ask them what your customers want you to improve? Employee ideas tend to be easier to implement and the whole process costs less and is faster than going systematically out to customers.
You can read all of the prior articles in the NPS series on our blog page here.
We have talked about asking customers what to improve, and improving it. We have mentioned the same approach for employees. I now want to introduce a hybrid concept: ask employees what to improve for customers. Let’s call it Customer-Employee NPS, or ceNPS.
Why should the customer be the only source of customer knowledge?
Customers are the best possible source for information about what they would like to see improved. As to how to improve it, well, they leave that up to you. Your employees have a different perspective. Most are aware of things that could be made better for customers. Many also have precise ideas about exactly how to do so. I therefore suggest testing the following survey with your employees to see what value it provides:
- How likely are our customers to recommend our company?
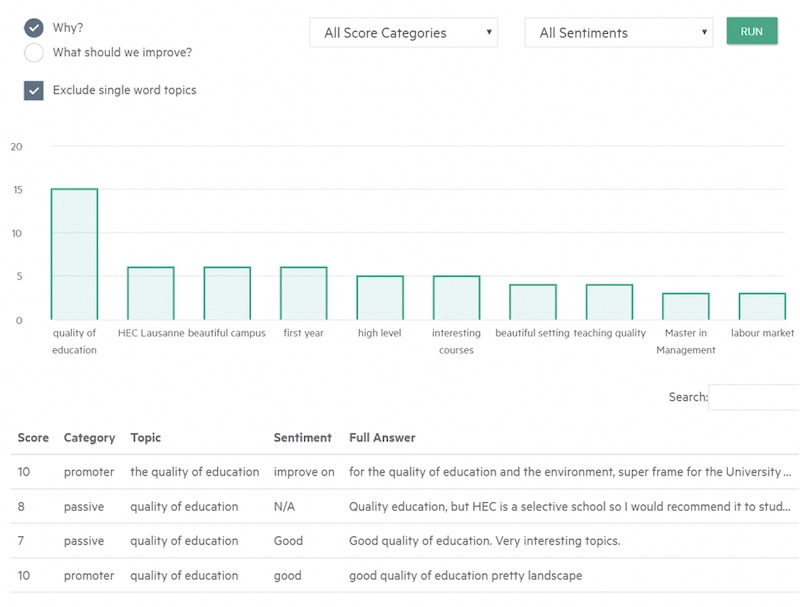
- Why?
- What should we improve for customers and how?
Use the same techniques as for customer research to prioritize the input. I don’t see why this would not work in all industries, bearing in mind that ‘customer’ means the direct customer of the company, which could be a retailer that sells onwards to end customers.
Compare with customer feedback
In a rational universe, there will be at least some overlap between customer feedback and employee views on what customers need. Compare the top five suggestions on both lists. Items that come up high on both lists are ideal; the customer’s expression of the need will match employee suggestions on how to implement the improvement.
Employees will have different ideas
Employees may have insights in areas that would not naturally occur to customers. One example that springs to mind happened shortly after HP set up a centralized pre-sales group in Bucharest, Romania. When the new operation started up, it would be fair to say that the people were quite passive, just doing what was asked. Sales people and resellers asked them to provide price quotations to customers, and they did that work well. Then the team supporting the Benelux noticed something. As negotiation cycles continued, sales people removed things from orders to meet a customer price point. Notably, offers for servers and storage that started with round-the-clock support services were often reduced to a cheaper business-hours-only proposal.
The Benelux team in Bucharest decided to systematically give the customers two proposals: one exactly as requested, and one with the service levels they believed the customers really needed, at a higher price. The initiative was a great success, with about half the customers taking the more appropriate service proposal at the higher price. For customers who accepted, it completely eliminated the situations where they would call during a weekend to be told that their contract did not cover the repair. A customer would never have thought of this double-proposal idea.
Employees should lead the implementation of their own ideas
Unless you have an excellent reason for not doing so, the person who made the suggestion should always lead implementation. Letting anyone else lead eliminates a career development opportunity and allows one aspect of human nature to creep into the picture: rejection of other people’s ideas. Just as the golden rule of project planning is “Those who implement must do the planning”, the golden rule of ideas is that the idea generator must drive the implementation. Yes, it is true that really creative people are usually awful at implementation, and that will be their career development opportunity.
Include your subcontractors and partners
If you use resellers and subcontractors, they should be included in your improvement culture too. Simply follow the same approach as for employees. I know of no example of any company doing this and am sure the reaction will be positive. It is to be expected that your partners will have privileged relationships with some of your end customers. You need to learn from them.
Next time
The next article will be about employee development in the context of customer experience work.
As is often the case, the above is a slightly-edited version of a chapter in one of our books; in this case Net Promoter – Implement the System All of our books are available in paperback and Kindle formats from Amazon stores worldwide, and from your better book retailers.







 Text2Data
Text2Data
 Next time
Next time



 Calling Promoters back
Calling Promoters back
